동적 데이터 소스와 스키마 이름
API를 개발할 때 Java Spring으로 프로젝트를 진행하고 싶었는데 어려움이 있었다.
해당 문제를 해결하고 세미나에서 발표한 내용에 대해 정리한다.
- 모든 아키텍처나 코드는 실제 서비스와 무관하며 설명을 위해 만든 부분임을 알린다.
API를 Java Spring으로 할 수 없었던 이유는 서비스의 DB구조 때문이었다.
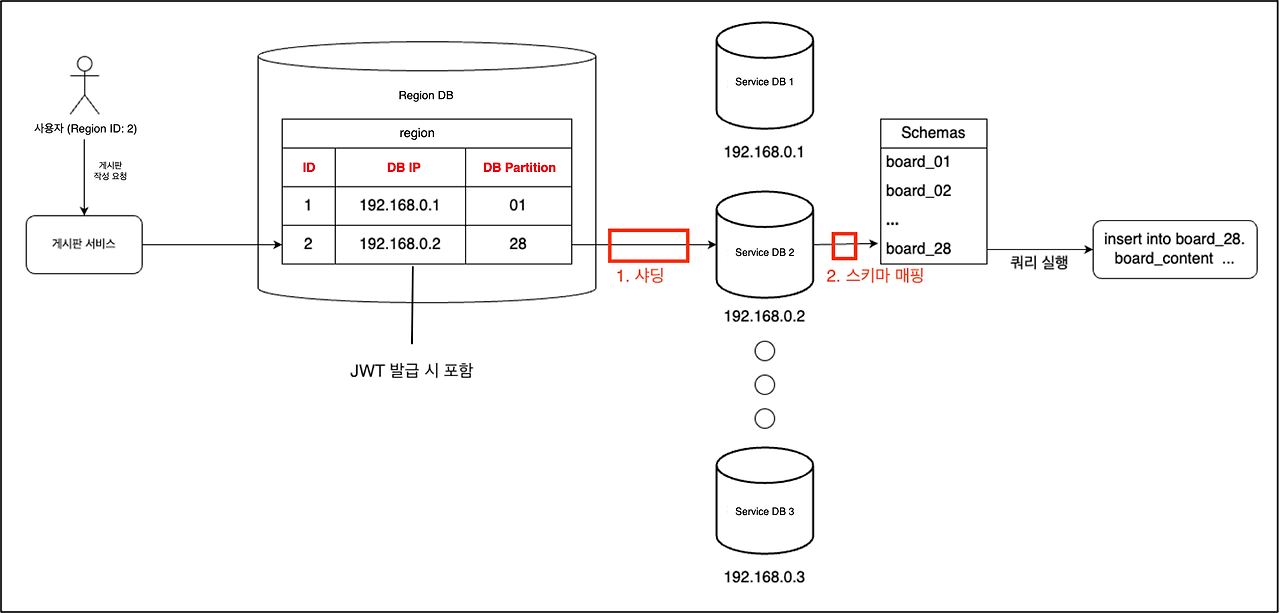
구조를 보면 DB 서버를 여러 대로 샤딩(Sharding) 하고 있고, 스키마도 분산되어 있다.
데이터를 저장할 때 유저가 속한 지역별로 데이터를 특정 DB서버의 특정 스키마에 저장해서 사용한다.
- board_01에서 01을 파티션이라고 칭한다.
특정 유저의 정보가 어떤 DB 서버의 몇 번째 파티션(스키마) 에 저장되어 있는지는 Region DB에 저장되어 있고, DB를 조회할 때마다 매번 Region DB를 질의하면 비효율적이므로 JWT에 발급해서 사용한다.
즉, 정리하면 아래 두 가지 작업을 처리했어야 했다.
- DB 서버 매핑 (Sharding)
- 스키마명 매핑
기존 프로젝트에서 처리한 방식
PHP 프로젝트
PHP는 요청이 들어올 때마다 실행되는 모델이기 때문에 Thread-Safety에 대한 걱정이 없었다. 그래서 PHP 스크립트가 실행될 때 JWT에 있는 값으로 DB 설정에 반영해주면 되었다.
NodeJS + Sequelize
NodeJS에서는 Entity 모델을 런타임 중 동적으로 생성할 수 있었다. 그래서 Map에 모델 객체들을 미리 생성하고 특정 DB 서버로의 커넥션을 부여했다.
즉, JWT에 있는 값을 기반으로 모델을 꺼내서 사용하면 된다. 모델을 DB 서버 수 x 파티션 수 만큼 메모리에 올리는 문제가 있었지만 처리는 가능했다.
JPA를 사용할 수 없는 이유
Spring 컨테이너 안에서 JPA를 사용하는 경우 위 예시처럼 DB 정보와 함께 모델을 매번 생성하는 게 불가능하다.
아래와 같이 DataSource를 싱글톤 빈으로 등록해서 사용해야 한다.

Schema name도 아래와 같이 애노테이션에 명시하면 앱이 실행될 때 Proxy를 생성한다.

그래서 DB 서버랑 스키마 명을 동적으로 어떻게 매핑할 수 있을 지에 대한 확신이 없었다.
팀에서는 이 문제 때문에 Java로 개발을 못하고 있었고, 자바로 개발된 프로젝트가 1개 있었는데 전부 JdbcTemplate을 사용했다.
- DataSource를 DB 서버 개수만큼 생성
- 파티션을 포함한 스키마명은 sql에 명시
정리하면 JPA를 사용하지 못하고 있었고, JdbcTemplate을 사용하더라도 DB 서버가 늘어나면 그것에 맞게 DataSource 개수도 추가해줘야 하는 문제가 있었다.
이 문제를 해결해야 했다.
1. DB Sharding
샤딩의 다양한 기법에 대해서는 아래 포스팅에서 정리했었다.
아래에서 설명할 방법은 앱 서버 수준에서 샤딩 DB를 매핑하는 방법이다.
AbstractRoutingDataSource
정보나 라이브러리를 찾으면서 삽질을 하던 중 Spring Jdbc에서 AbstractRoutingDataSource 라는 클래스를 확인할 수 있었다.
아래는 공식문서이다.

클래스 설명을 보면 Lookup key에 기반하여 Datasources 중에 1개에 대한 getConnection()을 호출해주는 클래스이다. (일반적으로 Thread에 할당된 TransactionContext를 사용한다고 명시되어있다.)

세부 구현을 살펴보면 determineTargetDataSources()라는 메서드로 DataSource를 선택한다.

해당 메서드를 보면 determineCurrentLookupKey()가 데이터 소스 Map의 Key가 되어서 데이터 소스를 선택하는 방식이다.
그래서 'JWT에 있는 DB Host를 LookupKey로 해서 Connection을 하면 되지 않을까?!'라는 생각을 가지게 되었다.
ThreadLocal
내용을 정리해보면 추상 메서드인 determineCurrentLookupKey()를 구현하면 되었다. 하지만 해당 메서드는 파라미터가 없고, getConnection() 내부에서 호출하는 방식이다.
Key를 정적인 필드에서 가져와야 했고, 각 요청(사용자)마다 다른 Key를 가져와야 했다.
그래서 ThreadLocal을 선택하게 되었다.
- Request Scope Bean vs ThreadLocal을 검토 하다가 ThreadLocal을 선택하게 되었다.
- Request Scope의 Bean도 내부적으로 ThreadLocal을 사용
- ThreadLocal은 샤딩 솔루션에 많이 사용되고 있었다.
아래는 AbstractRoutingDataSource의 구현체이다.
class MultiDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DBContextHolder.getIp();
}
}아래와 같이 ThreadLocal에 정적으로 접근할 수 있는 Holder 클래스를 만든다.
public class DBContextHolder {
private static final ThreadLocal<DbInfo> threadLocal = new ThreadLocal();
public static void setDbInfo(String ip, String partition) {
DbInfo dbInfo = new DbInfo(ip, partition);
threadLocal.set(dbInfo);
}
public static DbInfo getDbInfo() {
DbInfo dbInfo = threadLocal.get();
if(dbInfo == null) {
throw new IllegalStateException("DbInfo가 존재하지 않습니다.");
}
return dbInfo;
}
public static String getIp() {
DbInfo dbInfo = getDbInfo();
return dbInfo.ip();
}
public static String getPartition() {
DbInfo dbInfo = getDbInfo();
return dbInfo.partition();
}
public static void clear() {
threadLocal.remove();
}
}DbInfo 클래스에는 host와 partition을 담는다.
public record DbInfo(String ip, String partition) {
}지금까지 샤딩된 DataSource를 선택하는 코드를 작성했다.
MultiDataSourceManager
런타임 중에 AbstractRoutingDataSource의 dataSource를 추가할 수 있어야 한다.
AbstractRoutingDataSource를 관리하는 클래스를 하나 만들자.
@Slf4j
@Configuration
public class MultiDataSourceManager {
// key = hostIp, value = DataSource
// 동시성을 보장해야 하므로 ConcurrentHashMap을 사용한다.
private final Map<Object, Object> dataSourceMap = new ConcurrentHashMap<>();
private final AbstractRoutingDataSource multiDataSource;
private final DataSourceCreator dataSourceCreator;
public MultiDataSourceManager(DataSourceCreator dataSourceCreator) {
MultiDataSource multiDataSource = new MultiDataSource();
// AbstractRoutingDataSource의 targetDataSources를 지정
multiDataSource.setTargetDataSources(dataSourceMap);
// Key 대상이 없을 경우 호출되는 DataSource 지정 (해당 프로젝트에서는 Key가 없으면 예외가 터지도록 설계)
multiDataSource.setDefaultTargetDataSource(dataSourceCreator.defaultDataSource());
this.multiDataSource = multiDataSource;
this.dataSourceCreator = dataSourceCreator;
}
@Bean
public AbstractRoutingDataSource multiDataSource() {
return multiDataSource;
}
public void addDataSourceIfAbsent(String ip) {
if (!this.dataSourceMap.containsKey(ip)) {
DataSource newDataSource = dataSourceCreator.generateDataSource(ip);
try (Connection connection = newDataSource.getConnection()) {
dataSourceMap.put(ip, newDataSource);
// 실제로 사용하는 resolvedTargetDataSource에 반영하는 코드
multiDataSource.afterPropertiesSet();
} catch (SQLException e) {
throw new IllegalArgumentException("Connection failed.");
}
}
}
}이제 최초 JPA EntityLoading 시 필요한 defaultDataSource를 만들어야 한다.
추가로 hostIp를 입력받아서 DataSource를 만드는 책임도 아래 클래스에서 수행한다.
@Configuration
@RequiredArgsConstructor
public class DataSourceCreator {
private final DBProperties dbProperties;
public DataSource generateDataSource(String ip) {
HikariConfig hikariConfig = initConfig(ip);
return new HikariDataSource(hikariConfig);
}
public DataSource defaultDataSource() {
String defaultHostIp = dbProperties.getDefaultHostIp();
String defaultHostPartition = dbProperties.getDefaultPartition();
HikariConfig hikariConfig = initConfig(defaultHostIp);
HikariDataSource datasource = new HikariDataSource(hikariConfig);
// JPA 엔터티 최초 로딩 시 파티션 보관 필요
DBContextHolder.setDbInfo(defaultHostIp, defaultHostPartition);
return datasource;
}
private HikariConfig initConfig(String hostIp) {
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setJdbcUrl(getConnectionString(hostIp));
hikariConfig.setUsername(dbProperties.getUsername());
hikariConfig.setPassword(dbProperties.getPassword());
hikariConfig.setDriverClassName(dbProperties.getDriver());
return hikariConfig;
}
public String getConnectionString(String hostname) {
StringBuilder sb = new StringBuilder()
.append("jdbc:mysql://")
.append(hostname)
.append(":").append(dbProperties.getPort())
.append("/").append(dbProperties.getDefaultSchema());
return sb.toString();
}
}AbstractRoutingDataSource와 관련된 코드는 모두 작성했다.
Util 클래스 제공
이제 라이브러리의 사용처에서 ThreadLocal에 DbInfo를 넣어주고, DataSource가 없는 경우 생성해줘야 한다.
그런데 사용처에서는 ThreadLocal에 대해 직접적으로 다루지 않게 하고 싶었고, 편의성을 위해 라이브러리의 개념에도 접근할 필요가 없게 하고 싶었다.
- ThreadLocal은 다소 위험한 개념
- ThreadPool을 사용하는 경우 이전 Thread의 정보를 가져와서 잘못 쿼리가 나갈 수 있음
- 라이브러리의 개념에 접근해야 한다면 매번 라이브러리를 설명해야 함
그래서 사용자 편의를 위해 유틸성 클래스를 제공하기로 했다! 작성한 코드에서는 Filter, AOP 두 방식을 지원한다.
Filter로 처리
아래는 Filter로 처리를 구현한 코드이다.
@RequiredArgsConstructor
public class ShardingFilter extends OncePerRequestFilter {
private final MultiDataSourceManager multiDataSourceManager;
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
DbInfo dbInfo = JwtParser.getDbInfoByRequest(request);
DBContextHolder.setDbInfo(dbInfo);
// DataSource가 존재하지 않을 경우에 새로 생성해준다.
multiDataSourceManager.addDataSourceIfAbsent(dbInfo.ip());
try {
filterChain.doFilter(request, response);
} finally {
// ThreadPool을 사용하기 때문에 다른 요청에서 재사용할 수 없도록 반드시 clear()를 호출해야 한다.
DBContextHolder.clear();
}
}
}해당 필터를 사용해서 요청이 들어왔을 때 ThreadLocal에 DBInfo를 세팅하고 DataSource를 생성하는 로직을 비즈니스 로직에서 분리할 수 있다.
AOP로 처리
Batch 서버와 같이 Web 요청이 없는 경우 Filter로 처리가 불가능하다. 그래서 AOP 방식도 지원한다.
특정 메서드에 아래 애노테이션만 붙이면 샤딩을 처리할 수 있도록 처리하자.
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Sharding {
}아래와 같이 AOP 모듈을 구현한다.
@Aspect
@Component
@ConditionalOnBean(LoadDbInfoProcess.class)
@RequiredArgsConstructor
public class DataSourceAdditionAspect {
private final LoadDbInfoProcess loadDbInfoProcess;
private final MultiDataSourceManager multiDataSourceManager;
@Around("@annotation(com.violetbeach.sharding.module.aop.Sharding)")
public void execute(ProceedingJoinPoint joinPoint) throws Throwable {
DbInfo dbInfo = loadDbInfoProcess.loadDbInfo();
DBContextHolder.setDbInfo(dbInfo);
try {
// DataSource가 존재하지 않을 경우에 새로 생성해준다.
multiDataSourceManager.addDataSourceIfAbsent(dbInfo.ip());
joinPoint.proceed();
} finally {
DBContextHolder.clear();
}
}
}아래는 DBInfo를 가져오는 인터페이스이다.
public interface LoadDbInfoProcess {
DbInfo loadDbInfo();
}구현체는 사용자가 원하는 방식으로 구현할 수 있다.
ThreadLocal을 사용해도 되고, Security Context를 사용하거나 Spring Batch를 사용한다면 JobScope에서 ip와 partition을 꺼내는 등 원하는 방식으로 구현하면 된다.
아래는 테스트 결과이다.
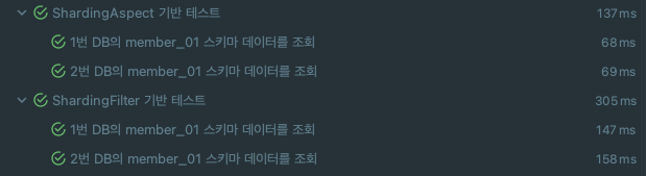
이렇게 해서 샤딩 문제가 해결되었다!
2. Dynamic Schema Name
1가지 문제가 남아있다. 스키마명을 jwt에 있는 partition을 사용해서 바꿔야 한다.
org.hibernate.resource.jdbc.spi.StatementInspector를 구현하면 된다. StatementInspector를 사용하면 기존 sql의 일부를 변경하거나 완전히 대체할 수 있다.
public class PartitionInspector implements StatementInspector {
@Override
public String inspect(String sql) {
String partition = DBContextHolder.getPartition();
return sql.replaceAll("@@partition_number", partition);
}
}이제 HibernatePropertiesCustomizer를 빈으로 등록하면 된다.
@Configuration
@RequiredArgsConstructor
public class HibernateConfig {
@Bean
public HibernatePropertiesCustomizer hibernatePropertiesCustomizer() {
return (properties) -> {
properties.put(AvailableSettings.STATEMENT_INSPECTOR, new PartitionInspector());
};
}
}Entity는 아래와 같이 설정한다.
@Entity
@Table(schema = "member_@@partition_number", name = "member")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
public Member(String username) {
this.username = username;
}
}MySQL에서는 @Table 애노테이션의 schema 옵션이 동작하지 않는다. 대신 catalog 옵션을 사용해야 한다.
아래는 테스트 결과이다.

쿼리도 문제 없이 나가고 DB 반영도 잘된다.

이제 Dyanmic Schema name 문제까지도 모두 해결되었다.
결과
다음은 통합 테스트의 결과이다. 전부 PASS했다.

이후 수행한 nGrinder로 운영 환경에서의 테스트도 잘 통과했고, 지금은 1년 반 넘게 문제 없이 사용하고 있다.
번외 1 - afterPropertiesSet
MultiDataSourceManager에서 데이터소스를 추가할 때마다 AbstractRoutingDataSource의 afterPropertiesSet() 메서드를 호출하고 있다.

해당 메서드는 아래와 같이 설정한 targetDataSources를 실제로 동작할 때 사용하는 resolvedDataSources에 반영하는 메서드이다.
- resolvedDataSources에 DataSource를 직접 추가할 수 없다. (가시성)
- 그래서 targetDataSources에 DataSource를 추가한 후 반드시 afterPropertiesSet()을 호출해야 한다.

afterPropertiesSet()은 InitializingBean의 빈이 등록되었을 때 실행되는 메서드이다. 런타임 중 DataSource를 추가로 생성하는 상황에서 적절한 의미를 외부로 뿜을 수 없었다.
나는 이부분을 Spring-jdbc에 PR을 올려서 이 부분의 가독성 문제를 언급했고 해결방안으로 메서드 추출(
refresh
initialize)을 제시했다.
해당 PR은 main 브랜치로 머지되었고 Spring Framework 6.1.0부터 반영된다고 한다.
번외 2 - 비동기
중간에 비동기 쓰레드를 사용할 경우 ThreadLocal의 데이터를 비동기 쓰레드로 옮겨줘야 한다.
해당 동작을위해 TaskDecorator의 구현체를 제공한다.
public class DBContextHolderDecorator implements TaskDecorator {
@Override
public Runnable decorate(Runnable runnable) {
DbInfo dbInfo = DBContextHolder.getDbInfo();
return () -> {
DBContextHolder.setDbInfo(dbInfo);
try {
runnable.run();
} finally {
DBContextHolder.clear();
}
};
}
}ThreadPoolTaskExecutor에서는 아래와 같이 Decorator를 등록할 수 있다.
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setTaskDecorator(new DBContextHolderDecorator());정리
코드는 실제 프로젝트에 적용된 코드는 아니고 설명을 위해 간소화된 코드입니다.
코드는 아래에서 확인할 수 있습니다.
'DB > MySQL' 카테고리의 다른 글
| Duplicated Data Handling (1) | 2024.07.12 |
|---|---|
| How we used Hibernate Filter and Inspector to dynamically add partition key to SQL queries? (0) | 2024.03.14 |
| 데이터베이스 파티셔닝과 샤딩 (31) | 2024.03.13 |
| Sharded MySQL Cluster 도입 배경과 개발기 (부제: 우당탕탕 좌충우돌 개발기) (0) | 2024.03.13 |
| How to Reset the MySQL Root Password (0) | 2024.01.09 |