It will be impossible to boot/start a Linux, or any other operating system, without the help of a boot loader. Boot loader plays a major role in bring up the system into running state. Infact the boot loader is the first program, that run's, when a computer is switched on.
Boot loader is the one, who transfers' control to an operating system kernel. Linux booting process requires special attention, and will be doing a dedicated post on that. In this post, we will be concentrating on GRUB(Grand Unified Boot loader), the default boot loader, for many Linux distributions.
GRUB was the result of a troubleshooting done by Erich Boleyn, to boot GNU Hurd(the operating system which was designed by GNU, as a free replacement of UNIX), with a micro kernel. Yoshinori K. Okuji, carried further work to advance the initial GRUB, and is called GRUB2.
The older version of GRUB(before grub2), is now called as GRUB-Legacy.
Why is GNU grub, the default boot loader for many Linux distributions?
Grub has got several added advantages, compared to previous boot loaders, and also many "Proprietary boot loader's".
- Grub can be used to load, almost all operating system's available, with the help of a function called chain-loading.
- Grub does not require the exact physical location of the operating system kernel in the hard disk. It just requires the hard disk number(like the first hard disk,second hard disk), and the partition number, along with the file name of the kernel. Because, GRUB understands the format in which kernel is made.
- You can modify, the booting options, like kernel parameter's and its location while booting, through GRUB command line.
How does GRUB command and graphical interface work together?
Grub has got a wonderful graphical interface where a user can select, the desired operating system from the menu.
The graphical interface also works in exactly the same way as command line interface. The only difference is that, a pre-configured configuration file contains the command which specifies the hard disk and kernel location(which otherwise have to be typed by hand, if you are using the command line interface.)
Learning Grub command's will be an added advantage, because it will help you to troubleshoot most of the booting problems etc.
What is the difference between Grub-Leagacy & GRUB-2?
There are some notable differences between the previous Grub-Leagacy and the new GRUB-2.
- Previously in Grub-Legacy partition number's of a hard disk, used to start from 0,1,2,..etc. But in GRUB-2 it starts the partition naming convention from 1,2,3..etc.
- It now recognizes many more new file system's like ext-4
- There are no more stages like stage-1,stage-1.5 etc, in grub image files, like the Grub-Legacy
- Grub-2 has started using modules which can be loaded as per requirement.
- GRUB-2 is capable enough to determine a hard disk partition using UUID's(Universally Unique Identifier)
- The configuration file name is grub.cfg(no more menu.lst & grub.config)
- The new grub-2 configuration file is highly configurable, compared to grub-legacy config file.
- GRUB-2 also supports EFI(Extensible Firmware Interface)
Grub Device Naming Convention
Grub device naming convention is totally different from the operating system partition naming convention. Its an important thing to keep in mind while working with grub.
The below table will be helpful in remembring the grub device naming convention.
(hd0) First hard disk installed in the computer
| (hd1) | Second Hard disk installed in the computer |
| (hd0,1) | First partition of first hard disk, in GRUB2 |
| (fd0) | Floppy disk |
| (hd1,2) | third partition of the second hard disk in grub-legacy |
hard disk number, partition number
How to install grub on a floppy disk or a partition?
When you are working on an already installed linux distribution, the grub package will be bydefault installed on the system.
I will be showing you, the example's of working with grub-legacy. Because any grub version number thats in the form 0.9x is grub-legacy now.(Please note the fact that grub-legacy is no longer under active developement.)
For this example, i will be working on a Red hat enterprise linux 5.
[root@localhost ~]# rpm -qa | grep grub
grub-0.97-13.5
[root@localhost ~]#the above shown package, will also provide you with a command called grub-install.
[root@localhost ~]# whereis grub-install
grub-install: /sbin/grub-install /usr/share/man/man8/grub-install.8.gz
[root@localhost ~]# rpm -qf /sbin/grub-install
grub-0.97-13.5
As you can clearly see from the above command results that the grub-install command comes from the package grub-0.97-13.5
You can simply install grub, on your desired partition, as shown below, with the help of grub-install command.
[root@localhost ~]# grub-install /dev/sda
Installation finished. No error reported.
This is the contents of the device map /boot/grub/device.map.
Check if this is correct or not. If any of the lines is incorrect,
fix it and re-run the script `grub-install'.
# this device map was generated by anaconda
(hd0) /dev/sda
[root@localhost ~]#In the above command, it will install grub in the MBR of the hard disk /dev/sda.
the above command result tells you an important fact to understand. It tells that, there is a device map file, and is asking us to check and confirm whether the file is correct or not.
Device map file is used by grub to identify the OS device names in a precise way. GRUB uses this file to map the device names of BIOS to operating system device names.This was devised, because there was inconstancies with, Linux operating system's device naming convention.
!http://www.slashroot.in/images/important note.gif
This file is configurable as per your requirement.
In the above example output of the /boot/grub/device.map tells that (hd0) in grub means /dev/sda in the operating system.
!http://www.slashroot.in/images/important note.gif
Whenever you install GRUB, on any of your partition, it gets installed and images are put under the directory "boot" in that partition.
If you want to install grub, under a directory other than the default "boot", you need to specify the boot directory with a command line argument to grub-install command.
Imagine that you want to install grub, on one of your external hard disk, and is currently mounted under /mydisk. lets see how to do it.
[root@localhost ~]# grub-install --root-directory=/mydisk/grub/ /dev/sdbmount point = /mydisk/grub
default grub mounted point → boot directory
Booting an OS from grub command line
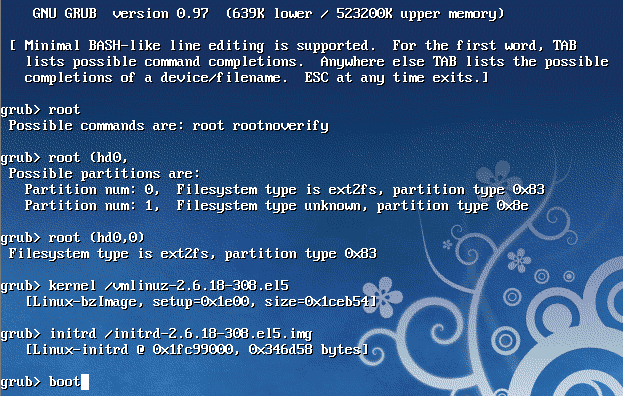
Booting an operating system from grub command line is quite simple. You just need to specify the partition where your kernel and initrd images are present before entering the boot command.
press "c" when you are in grub menu selection area. You will be presented with a grub> grub console, as shown below. This is not your Linux console, its a grub console, and will only accept grub specific commands.
!https://www.slashroot.in/sites/default/files/grub command line.png
fortunately this command line interface supports TAB-completion. So you dont need to remember the exact full name of the kernel,initrd & the partition numbers.
Infact whenever you are unable to boot, you can do a hit and trial method in multiple partition.
After entering the grub console by pressing "C", set the root partition and hard disk with the command "root"(always take help from tab completion)
press TAB after "root(", and you will be shown the possible hard disk and partitions.
After selecting hard-disk and partition, you need to tell the name of the kernel(as i told before, grub understands kernel file formats, and will by default look @ /boot in the partition, and so tabing will work here also.)
type "kernel" followed by a / with vmlinuz(the default kernel package name, do tabing to complete the filename.)
Similarly you can give initrd file name and finally enter the command boot, to boot with the currently entered configuration.
!http://www.slashroot.in/images/important note.gif
you can use the same technique to boot a system, with a wrong or corrupted grub configuration.
What is chain loading in grub?
You might have noticed that grub is capable of loading different operating system. like for example, you can even load a windows operating system with the help of grub(Infact if you install Linux after windows, everything is done automatically by the installer for you).
Grub achieves this ability to load multiple or even proprietary operating system, with the help of chain loading.
chain loading is the method used by grub, in which it transfers' the control of booting that operating system to its native boot loader.
Grub → Control of booting that operating system → native boot loader
when Linux is installed after windows, GRUB stage-1 overwrites MBR(After removing the windows boot loader, and placing it in the volume boot record of the windows C partition).
!http://www.slashroot.in/images/important note.gif
Volume boot record is similar to MBR. its the first sector of a partition. However MBR is the first sector of a hard-disk(first 512 bytes of a hard disk).
the grub config file entry for windows chain loader looks like the below.
title Windows Operating System
rootnoverify (hd0,0)
chainloader +1the first line "title" will be shown to you in the selection list at boot time in grub. the second line is similar to the "root" command, we previously used to boot the system using grub command line.
The only difference between "root" and "rootnoverify" is that, "rootnoverify" will not try to mount the file-system (because it will mostly be an unknown file system).
The third line tells to load the first sector of that partition, or say volume boot record(which will contain windows boot loader). Now windows will boot normally, because its being booted by windows boot loader.
Understanding GRUB stages
GRUB-legacy consists of three stages. They are as below.
- GRUB stage 1 (MBR Side, loading grub stage-1.5)
- GRUB stage 1.5 (MBR side - GRUB stage 1.5 - First partition)
- GRUB stage 2 (displaying GRUB menu)
In a hard-disk, if you are using MBR partition style, then the first sector of your hard disk(the first 512 bytes of your hard disk), will contain the boot loader & the partition table
440 bytes is for the boot loader and the remaining is for partition table(remember that, i am talking about MBR partition scheme).
GRUB stage 1 resides in the MBR of the hard disk.
Due to the extremely small size of the MBR(512 bytes), the grub stage-1 does the small job of loading grub stage-1.5, which resides in the blocks immediately after the MBR and before the first partition. This area, where grub-1.5 resides is roughly around 30kb.
Grub stage 1.5 is very much important, because it contains file system driver's to open the file system specific stage 2(which will open file from a known location in the partition, like /boot/). stage 2 is responsible for displaying the grub menu(because the menu is based on the config file grub.conf which is inside /boot)
How does the grub config file look like?
Grub config file looks like the below shown entries.
[root@localhost ~]# cat /boot/grub/grub.conf
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You have a /boot partition. This means that
# all kernel and initrd paths are relative to /boot/, eg.
# root (hd0,0)
# kernel /vmlinuz-version ro root=/dev/sda2
# initrd /initrd-version.img
#boot=/dev/sda
default=0
timeout=5
splashimage=(hd0,0)/grub/splash.xpm.gz
hiddenmenu
title CentOS (2.6.18-238.12.1.el5)
root (hd0,0)
kernel /vmlinuz-2.6.18-238.12.1.el5 ro root=LABEL=/ rhgb rhgb quiet
initrd /initrd-2.6.18-238.12.1.el5.img
the original file is infact, is /etc/grub.conf, there is a symbolic link given from this /etc/grub.conf to /boot/grub/grub.conf file
[root@localhost etc]# ll /etc/grub.conf
lrwxrwxrwx 1 root root 22 Jan 28 2011 /etc/grub.conf -> ../boot/grub/grub.conf
"default=0" tell's the default operating system to boot, if nothing is selected within a specified timeout during boot, from the grub menu. 0 means the first entry(which in the above case is centos.) default=1 will boot the second title entry as the default operating system if nothing selected within the specified timeout during the boot.
"timeout=5", this specifies the time in seconds, to wait before the default option is selected to boot automatically by the grub.
"splashimage"
, specifies the location of the grub background image to show, behind the menu list(you can put your pic there
!http://www.slashroot.in/sites/all/libraries/ckeditor/plugins/smiley/images/regular_smile.gif
).
"hiddenmenu" will keep the menu hidden if no key is pressed during the grub boot screen(and will bydefault boot the default operating system without showing the menu)
'LINUX > Boot-up Process' 카테고리의 다른 글
| How does the Linux boot process work? - Quora (0) | 2023.08.26 |
|---|---|
| How does a kernel mount the root partition? (0) | 2023.08.25 |
| Linux Booting Process: A step by step tutorial for understanding Linux boot sequence (0) | 2023.08.24 |
| #1 GPT - GUID Partition Table (1) (0) | 2023.08.22 |
| What is MBR and GPT partition table (0) | 2023.08.22 |








{kind=link}
{kind=link}
{kind=link}