Trusty is a secure Operating System (OS) that provides a Trusted Execution Environment (TEE) for Android. The Trusty OS runs on the same processor as the Android OS, but Trusty is isolated from the rest of the system by both hardware and software. Trusty and Android run parallel to each other. Trusty has access to the full power of a device’s main processor and memory but is completely isolated. Trusty's isolation protects it from malicious apps installed by the user and potential vulnerabilities that may be discovered in Android.
Trusty is compatible with ARM and Intel processors. On ARM systems, Trusty uses ARM’s Trustzone™ to virtualize the main processor and create a secure trusted execution environment. Similar support is also available on Intel x86 platforms using Intel’s Virtualization Technology.
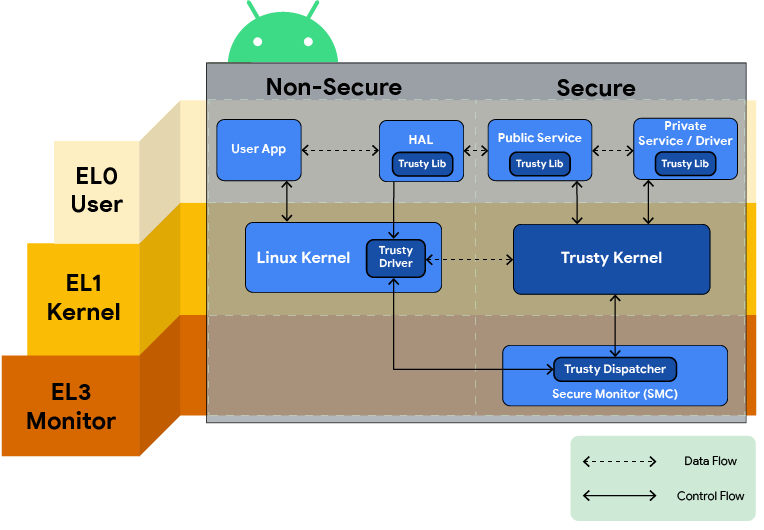
Figure 1. Trusty overview diagram.
Trusty consists of:
- A small OS kernel derived from Little Kernel
- A Linux kernel driver to transfer data between the secure environment and Android
- An Android userspace library to communicate with trusted applications (that is, secure tasks/services) via the kernel driver
Note: Trusty and the Trusty API are subject to change. For information about the Trusty API, see the API Reference.
Why Trusty?
Other TEE operating systems are traditionally supplied as binary blobs by third-party vendors or developed internally. Developing internal TEE systems or licensing a TEE from a third-party can be costly to System-on-Chip (SoC) vendors and OEMs. The monetary cost combined with unreliable third-party systems creates an unstable ecosystem for Android. Trusty is being provided to its partners as a reliable and free open source alternative for their Trusted Execution Environment. Trusty offers a level of transparency that is just not possible with closed source systems.
Android supports various TEE implementations so you are not restricted to using Trusty. Each TEE OS has its own unique way of deploying trusted applications. This fragmentation can be a problem for trusted application developers trying to ensure their apps work on every Android device. Using Trusty as a standard helps application developers to easily create and deploy applications without accounting for the fragmentation of multiple TEE systems. Trusty TEE provides developers and partners with transparency, collaboration, inspectability of code, and ease of debugging. Trusted application developers can converge around common tools and APIs to reduce the risk of introducing security vulnerabilities. These developers will have the confidence that they can develop an application and have it reused across multiple devices without further development.
Applications and services
A Trusty application is defined as a collection of binary files (executables and resource files), a binary manifest, and a cryptographic signature. At runtime, Trusty applications run as isolated processes in unprivileged mode under the Trusty kernel. Each process runs in its own virtual memory sandbox utilizing the memory management unit capabilities of the TEE processor. The build of the hardware changes the exact process that Trusty follows, but for example, the kernel schedules these processes using a priority-based, round-robin scheduler driven by a secure timer tick. All Trusty applications share the same priority.
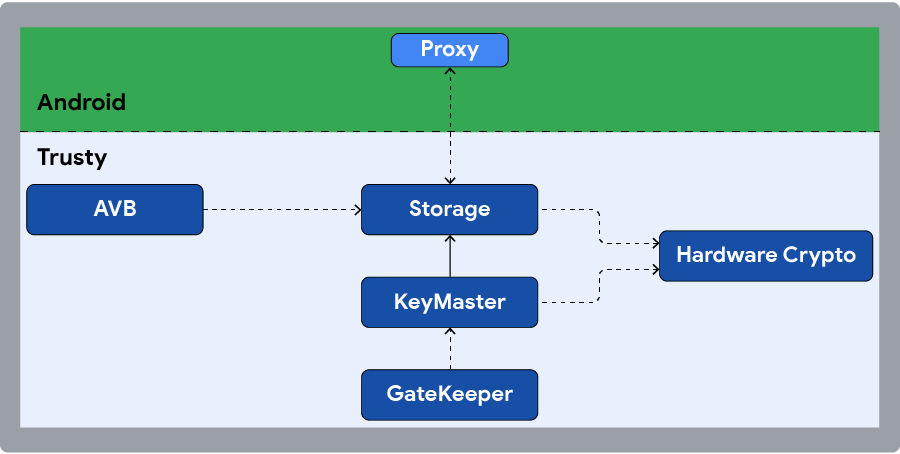
Figure 2. Trusty application overview.
Third-party Trusty applications
Currently all Trusty applications are developed by a single party and packaged with the Trusty kernel image. The entire image is signed and verified by the bootloader during boot. Third-party application development is not supported in Trusty at this time. Although Trusty enables the development of new applications, doing so must be exercised with extreme care; each new application increases the area of the trusted computing base (TCB) of the system. Trusted applications can access device secrets and can perform computations or data transformations using them. The ability to develop new applications that run in the TEE opens up many possibilities for innovation. However, due to the very definition of a TEE, these applications cannot be distributed without some form of trust attached. Typically this comes in the form of a digital signature by an entity trusted by the user of the product on which the application runs.
Uses and examples
Trusted execution environments are fast becoming a standard in mobile devices. Users are relying more and more on their mobile devices for their everyday lives and the need for security is always growing. Mobile devices with a TEE are more secure than devices without a TEE.
On devices with a TEE implementation, the main processor is often referred to as “untrusted”, meaning it cannot access certain areas of RAM, hardware registers, and write-once fuses where secret data (such as, device-specific cryptographic keys) are stored by the manufacturer. Software running on the main processor delegates any operations that require use of secret data to the TEE processor.
The most widely known example of this in the Android ecosystem is the DRM framework for protected content. Software running on the TEE processor can access device-specific keys required to decrypt protected content. The main processor sees only the encrypted content, providing a high level of security and protection against software-based attacks.
There are many other uses for a TEE such as mobile payments, secure banking, multi-factor authentication, device reset protection, replay-protected persistent storage, secure PIN and fingerprint processing, and even malware detection.
'ANDROID' 카테고리의 다른 글
| When to use guard let rather than if let (0) | 2024.03.11 |
|---|---|
| [Admob] Google Admob 조지기 직전 (197/3.6.27 release) (0) | 2023.12.20 |
| [Trouble Shooting] AccessToken 의 특이점 발견 (31) | 2023.08.08 |
| [Android] Classpath 문제 해결하기 (0) | 2023.06.26 |
| [Android Update] access_token (0) | 2023.06.20 |